Inference is not learning. The recursive content stack.
· 9 min readIn March, Andrej Karpathy [open-sourced AutoResearch](https://github.com/karpathy/autoresearch): an agent that ran 700 ML experiments without supervision, surfaced 20 training optimizations, and never required a human in the loop. He called the moment the loopy era — the ["final boss battle,"](https://www.nextbigfuture.com/2026/03/andrej-karpathy-on-code-agents-autoresearch-and-the-self-improvement-loopy-era-of-ai.html) in his words.
That framing has been the gravitational center of agentic-learning discourse on AI Twitter ever since. And it should be — it's the right framing. But the conversation keeps orbiting research and code. Almost no one is asking the obvious adjacent question:
> What does the loopy era look like for content?
Because content generation, as a problem, has the same shape. You have an action space (every possible post). You have an environment (the platform). You have a reward signal (engagement). You have an obvious objective: post things that perform. The whole thing is a partially-observable RL problem in plain sight.
And almost no one is treating it like one.
Inference is not learning.
Here is the uncomfortable observation. The model that wrote your last 50 posts has zero memory of which ones worked. None. The signal exists — likes, saves, shares, watch time, whatever your platform reports — but it never makes it back to the system that generated the post. The data dies on the floor of the dashboard.
Run the same prompt next week. You get the same baseline output. The system is not getting better. Generation is improving rapidly across the industry — better models, better prompts, better UX over the same models. Learning is not. Not in any meaningful per-brand sense.
That gap — between what the model can produce in a vacuum and what it should produce given everything that has actually performed for you — is the most underbuilt surface in the entire AI content stack right now. It's also where the entire moat lives.
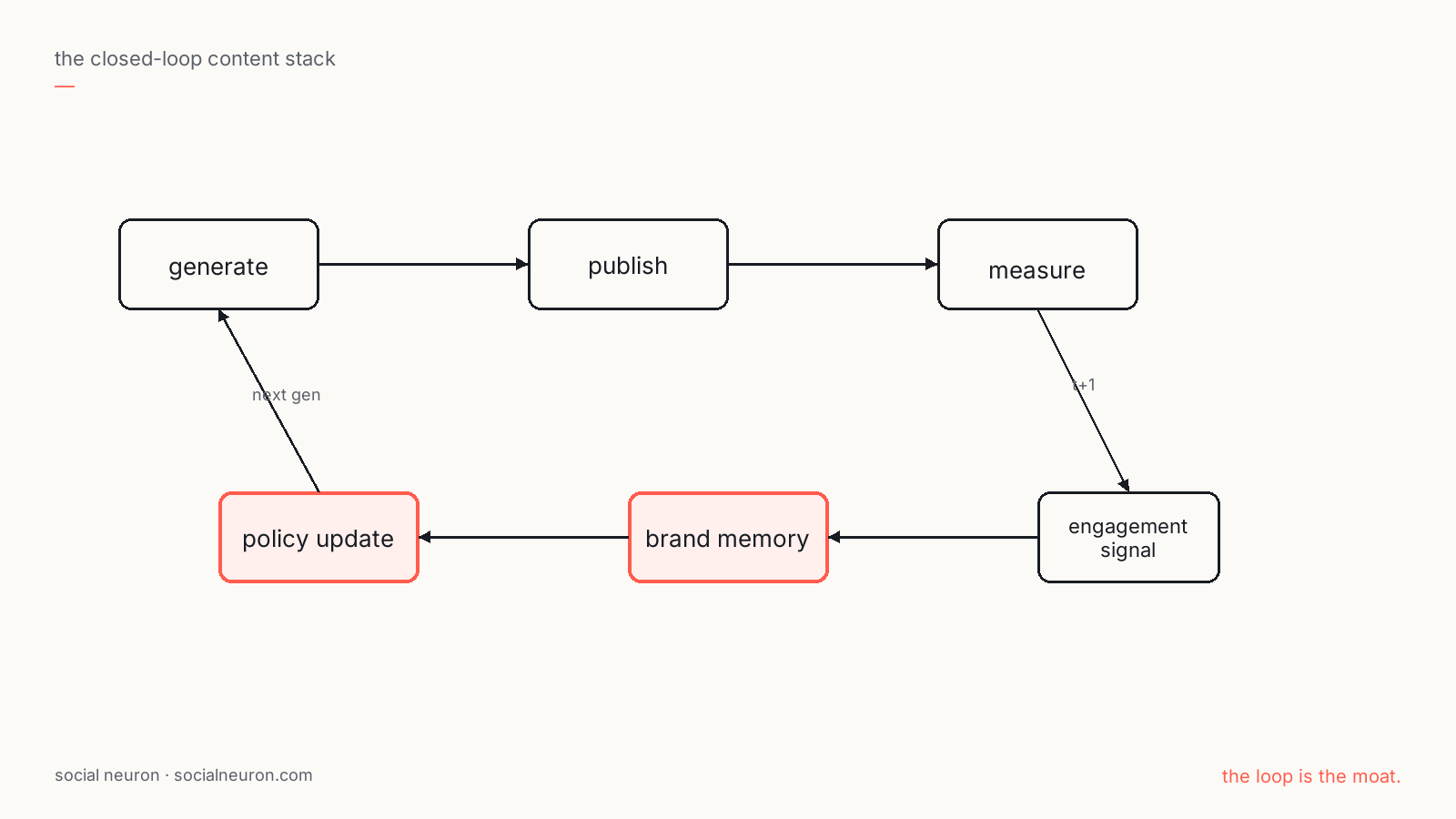
Four ingredients of agentic content learning.
If you actually want to ship a system that learns from its own production signal, here's the minimum architecture. None of these are exotic — they're each well understood individually in the agent literature. Almost no content tool has all four.
:::ingredients
- Per-brand episodic memory. A hippocampus, not a context window. Every post a brand publishes — with its full content, audience, distribution, and outcome — becomes a queryable episode. The system reasons over its own history rather than starting from zero each session.
- Outcome-conditioned retrieval. When the agent generates the next post, the retrieval step is biased by performance. Winning trajectories surface. Losing ones get downweighted. This is closer to RL-style trajectory sampling than to vanilla RAG.
- A mid-loop critic. Before publish, a learned critic — fine-tuned or retrieved against your brand's actual outcomes — interjects. Predicted-engagement scoring, voice-drift detection, structural critique. Cheap, fast, before the real-world reward comes in.
- Self-play on synthetic engagement. For exploration, the system simulates audience reaction on candidate variants — using the brand's own historical signal as the discriminator — and selects from the synthetic distribution. Real-world publication then provides the ground truth that updates the model.
:::
You've seen this list before.
If you stare at that list for a second — episodic memory, continual learning, metacognition, exploration via self-play — it maps almost exactly onto Demis Hassabis's recent talks on the missing AGI ingredients. Different domain. Same architectural gaps.
That's not a coincidence. Content generation is one of the cleanest possible test environments for these capabilities: cheap rollouts, clear-ish reward, dense signal, low risk. If recursive self-improvement is going to work anywhere first in production, it'll work here. [SciTalk (arXiv 2504.18805)](https://arxiv.org/abs/2504.18805) is already showing this in the academic setting — closed-loop content generation with iterative feedback, measurable improvement curves over rounds.
A note of caution: even closed loops can deceive themselves.
The same SciTalk paper is also the most useful warning shot in the literature. Across five iterations of their multi-agent system, model-judged scores kept rising while human-judged scores collapsed in dimensions the internal critic couldn't perceive. The system Goodhart-ed against its own judge.
The lesson is precise: the loop only earns its compounding when it's grounded in real-world engagement signal, not internal critic agreement. If your only feedback comes from another LLM scoring outputs against a fixed rubric, you'll iterate confidently into worse content while your dashboard stays green. Real outcome reward — likes, saves, watch-through, replies, conversions — must be the primary training signal. Rubrics and process scores are intermediate. Anyone shipping closed-loop content systems needs a divergence canary that catches this drift before it ships to production.
Why most AI content SaaS is structurally pre-loopy.
Most "AI content platforms" you've heard of are inference wrappers. The pitch is some flavor of more inference per dollar: better prompts, faster generation, nicer UI over someone else's model. They're the equivalent of a static image classifier you call once per request and never train again.
This is fine, in the sense that it's useful. It's also a structurally capped business. As foundation models keep improving, the wrapper layer compresses. Distribution becomes the only moat, and distribution is brutal.
The interesting builds — the ones that won't compress — are the ones where the system actually learns. Engagement → memory → policy → next generation. A measurable improvement curve, per brand, that isn't just the underlying model getting better.
==Software isn't a moat. Models aren't a moat. The loop is the moat.==
What we're composing — and what we're protecting.
The honest framing: nobody we know has the whole closed-loop content stack working end-to-end yet, and that includes us. The architecture is composed from primitives that are already well-formalized in the research:
- The reflection loop — Reflexion (Shinn et al., 2023): a verbal feedback signal stored in episodic memory, used to condition the next generation.
- The per-stage rubric scoring — SciTalk's per-agent feedback agents and AgentPRM's process reward models: dense intermediate signal that locates which step caused failure.
- The outcome grounding — straightforward: real engagement is the primary training signal, not internal agreement.
- The brand-scoped specialization — this is the part that's domain-specific. Generic agent loops don't learn voice, audience, or platform fit; per-brand loops do.
Our work is composing those into a content lifecycle that runs in production, with the data plumbing and the anti-Goodhart guardrails to keep it honest. The architecture pattern is public; the specific tuning, the brand-memory structure, the engagement model, the per-platform exposure logic — that's the implementation, and that's the bit that compounds.
The loop is the moat.
If your content engine doesn't get measurably better month-over-month from its own performance signal — its own production data, its own brand-specific reward — you've built an inference wrapper, not a learning system. That's a fine product. It's not a moat.
The loopy era for content is just starting. We think the next eighteen months in this category will look a lot like the last eighteen months in agentic ML research: a slow accumulation of unglamorous infrastructure (memory, retrieval, critics, evals, divergence canaries) that suddenly composes into a system that doesn't need a human in the loop to keep getting better.
That's the bet, anyway.